[SpringBoot] Java로 웹 크롤러 구현하기(feat.네이버 쇼핑 검색 데이터 크롤링하기)
안녕하세요. delay100입니다.
오랜만에 게시글을 작성해보는데요! 오늘의 주제는 크롤링 만들기. 그 중에서도 네이버 쇼핑 크롤러 만들기입니다 ㅎㅎ.

저는 크롤링은 이번에 처음 만들어보았는데요,
크롤러를 만들고 난 후에 이 포스팅을 쓰는 시점에서 크롤링을 생각해보면 html을 한참 바라보는 일이라고 생각합니다.
따라서 크롤링의 전반적인 개념은 1. html 태그 구조를 파악하고 2. 해당 태그에 들어있는 정보를 우리쪽으로 긁어온다! 고 생각하면 됩니다.
이런 크롤러의 특성상 크롤링을 할 사이트의 태그들이 업데이트 되면 다시 태그 구조를 파악해야하는 번거로움이 존재합니다.... 노가다예요..
서론은 이쯤 하고 실제 코드를 보면서 크롤링을 해봅시다!
*주의!
크롤링 특성 상 실시간 네이버 쇼핑 값을 이용하고 있습니다. 블로그 글을 읽는 시점에는 네이버의 태그 값이 변경되었을 수 있습니다!
1. Springboot 프로젝트 생성
Springboot 프로젝트 생성은 아래의 포스팅의 1. Springboot 프로젝트 생성을 참고해주세요.
https://delay100.tistory.com/163
[SpringBoot] Spring프로젝트 Postman에서 확인하기
안녕하세요. delay100입니다.오늘은 Spring GET요청에 대해서 Postman에서 확인하는 방법을 적어보았습니다.1. SpringBoot 프로젝트 생성먼저, start.spring.io에서 아래와 같은 설정으로 프로젝트를 만들어줍
delay100.tistory.com
**참고
저의 개발 환경은 아래와 같습니다.
- java - 17
- Springboot - 3.3.2
- Project - Maven
- Packaging - Jar
- Dependencies - Spring Web, Lombok
https://start.spring.io/ 또는 IDE에서 프로젝트 생성해주세요. Springboot 버전은 3.n.n버전이면 상관 없습니다.
저는 Maven 프로젝트로 진행했으나, Gradle도 무관합니다.

2. 추가 Dependency 설정(Jsoup, Selenium)
2가지의 Dependency를 추가적으로 설정해줘야합니다. 크롤링에 있어서 가장 핵심인 라이브러리들이에요.
Jsoup?
- HTML을 다루기 위한 Java 라이브러리로, 웹 페이지를 파싱하고, 데이터 추출 및 조작을 간단히 처리할 수 있음
- Document, Elements, Element를 사용하기 위해 필요함
Selenium?
- 웹 애플리케이션을 테스트하거나 브라우저를 자동화하는 데 사용하는 도구
- 특히 동적으로 생성되는 웹 페이지의 데이터를 다룰 때 유용
- By, JavascriptExecutor, WebDriver, ChromeDriver등을 사용하기 위해 필요함
이 2가지 라이브러리는 설정파일(build.gradle 혹은 pom.xml)에 아래와 같이 명시해주면 프로젝트 내에서 사용할 수 있습니다.
- Project가 Gradle인 경우
// build.gradle
dependencies {
implementation 'org.jsoup:jsoup:1.15.4'
implementation 'org.seleniumhq.selenium:selenium-java:latest.release'
}- Project가 Maven인 경우
// pom.xml
<dependencies>
..다른 dependency들..
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.4</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
</dependency>
</dependencies>3. Controller, DTO
특정 API를 호출하면 해당 키워드와 관련된 값을 크롤링하는 방식을 사용할 것입니다. 따라서 Controller와 DTO를 만들어주었습니다.
요청 URL 예시
http://localhost:8081/crawl2?keyword=삼겹살&page=1
http://localhost:8081/crawl2?keyword=호빵&page=2
- controller/CrawlerController
package com.example.demo.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.example.demo.crawler.NaverShoppingCrawler;
import com.example.demo.crawler.SeleniumNaverShoppingCrawler;
import com.example.demo.dto.Product;
import java.util.List;
@RestController
public class CrawlerController {
private final SeleniumNaverShoppingCrawler seleniumCrawler;
public CrawlerController(SeleniumNaverShoppingCrawler seleniumCrawler) {
this.seleniumCrawler = seleniumCrawler;
}
@GetMapping("/crawl2")
public List<Product> crawl2(
@RequestParam String keyword,
@RequestParam(defaultValue = "1") int page) {
try {
return seleniumCrawler.getShoppingData(keyword, page);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}- dto/Product
package com.example.demo.dto;
public class Product {
private int num;
private String title;
private String mall;
private String price;
public Product(int num, String title, String mall, String price) {
this.num = num;
this.title = title;
this.mall = mall;
this.price = price;
}
public int getNum() {
return num;
}
public String getTitle() {
return title;
}
public String getMall() {
return mall;
}
public String getPrice() {
return price;
}
@Override
public String toString() {
return "Product{" +
"num= '" + num + '\'' +
"title='" + title + '\'' +
", mall='" + mall + '\'' +
", price='" + price + '\'' +
'}';
}
}4. 크롤러 구현하기
각 코드에 대한 설명은 주석으로 달아두었습니다.
@Service
public class SeleniumNaverShoppingCrawler {
// 이 안에 크롤러 메소드 작성
}크롤러 코드만 넣을 Service 클래스를 작성합니다.
4-1. 크롤링 기본 코드(틀)
/**
* 네이버 쇼핑 데이터를 크롤링하여 반환
*
* @param keyword 검색 키워드
* @param page 페이지 번호
* @return List<Product> 크롤링된 상품 목록
* @throws InterruptedException 스레드 대기 시 발생할 수 있는 예외
*/
public List<Product> getShoppingData(String keyword, int page) throws InterruptedException {
// 크롤링 결과를 담을 리스트 초기화
List<Product> result = new ArrayList<>();
int num = 1; // 상품 번호 초기화
// Selenium WebDriver 설정
ChromeOptions options = new ChromeOptions(); // 크롬 옵션 객체 생성
WebDriver driver = new ChromeDriver(options); // WebDriver 객체 생성
try {
// 네이버 쇼핑 검색 URL 생성
String url = String.format(
"https://search.shopping.naver.com/search/all?pagingIndex=%d&query=%s", page, keyword);
driver.get(url); // URL로 이동
// 페이지 끝까지 스크롤
((JavascriptExecutor) driver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
Thread.sleep((int) ((Math.random() + 0.1) * 300)); // 랜덤 대기 시간 추가 (부하 방지)
// 상품 리스트 크롤링
List<WebElement> productElements = driver.findElements(By.cssSelector(".basicList_list_basis__uNBZx > div > div"));
for (WebElement element : productElements) {
// 상품 HTML 파싱 및 Product 객체 생성
Product product = parseProduct(num, element.getAttribute("innerHTML"));
if (product != null) {
result.add(product); // 결과 리스트에 추가
num++; // 상품 번호 증가
}
}
} finally {
driver.quit(); // 브라우저 종료
}
return result; // 크롤링 결과 반환
}Controller에서 직접 호출하는 메소드입니다. CrawlerController에서 아래와 같이 getShoppingData메소드를 호출하고 있습니다.
// CrawlerController 中 일부
return seleniumCrawler.getShoppingData(keyword, page);
여기서는 WebDriver, ChromeDriver를 이용하여 브라우저를 제어합니다.
- Selenium 명령을 Chrome 브라우저로 전달:
Selenium WebDriver는 ChromeDriver를 통해 Chrome 브라우저를 제어합니다.
예를 들어, "이 URL로 이동해라"라는 명령을 ChromeDriver가 Chrome 브라우저에 전달합니다.
- Chrome 브라우저와의 통신 중개:
Selenium 명령과 Chrome 브라우저 간의 통신을 처리합니다.
WebDriver는 직접 브라우저와 통신하지 않고 ChromeDriver를 통해 제어합니다.
원하는 요소를 가져오는 크롤링의 핵심 코드는 아래와 같습니다.
List<WebElement> productElements = driver.findElements(By.cssSelector(".basicList_list_basis__uNBZx > div > div"));By.cssSelector를 이용하는데요, html내에서 css값으로 요소를 찾아옵니다.
우리는 쇼핑 상품을 크롤링 할 것이기때문에, 먼저 네이버 쇼핑에 접근해서 html요소를 파악해야합니다.

개별 상품을 감싸고 있는 상단의 div태그를 찾습니다. basicList_list_basis__uNBZx태그를 기준으로 아래에 div태그가 하나 있고, 그 아래에 개별 상품들이 들어있는 것으로 보입니다. 따라서 cssSelector를 이용해서 개별 값들을 list<Element> 형태로 가져옵시다.
그런 다음, 각각의 상품들에 대해서 상품명, 상품가격, 쇼핑몰을 뽑아오도록 해야합니다.
for (WebElement element : productElements) {
// 상품 HTML 파싱 및 Product 객체 생성
Product product = parseProduct(num, element.getAttribute("innerHTML"));
if (product != null) {
result.add(product); // 결과 리스트에 추가
num++; // 상품 번호 증가
}
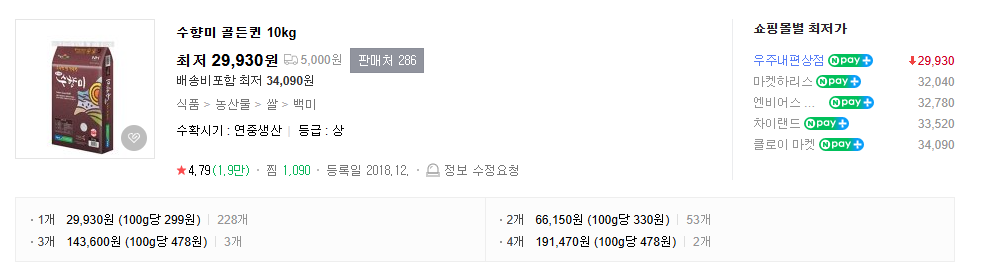
}여기서 element는 아래의 사진과 같이 상품 하나를 감싸고 있는 WebElement 객체입니다.

이제 이 객체들 내부의 값을 parseProduct 메소드를 이용해 파싱을 해보겠습니다.
4-2. 크롤링으로 가져온 정보 추출
/**
* HTML을 파싱하여 Product 객체 생성
*
* @param num 상품 번호
* @param html 상품 정보를 담고 있는 HTML
* @return Product 객체
*/
private Product parseProduct(int num, String html) {
Document doc = Jsoup.parse(html);
// 상품 제목, 가격, 쇼핑몰 정보 추출
String title = extractTitle(doc);
String price = extractPrice(doc);
String mall = extractMall(doc);
if (title == null || price == null || mall == null) return null;
System.out.println("num= " + num + " ,title= "+ title +" ,mall= "+ mall +" ,price= "+ price);
return new Product(num, title, mall, price);
}이제 하나의 상품 객체들을 가지고 온 후 상품명, 상품가격, 쇼핑몰 정보를 가져오도록 합니다.
Document내에서 각각 가져오는 코드들도 메소드로 분리해두었습니다.
4-2-1. extractTitle(상품명), 4-2-2. extractPrice(상품가격), 4-2-3. extractMall(쇼핑몰)
4-2-1. 크롤링으로 가져온 정보 추출 - 1 상품명
/**
* 상품 제목 추출
*/
private String extractTitle(Document doc) {
Elements titleElements = doc.select(
"a.product_link__TrAac, a.superSavingProduct_link__nlArK, a.adProduct_link__NYTV9");
return !titleElements.isEmpty() ? titleElements.attr("title").isEmpty()
? titleElements.text()
: titleElements.attr("title") : null;
}여기서 주의해야할 점은 상품명이 모두 같은 태그가 아니라는 점입니다.
현재 시점(2024-11-28)에는 총 3가지의 태그 종류가 있습니다. 이 값들을 doc.select를 이용해 추출해옵니다.
- 1번 경우 - 상단에 주황색 해시태그가 달려있는 경우
- 태그명: a.adProduct_link__NYTV9


- 2번 경우 - 상단에 파란색 해시태그가 달려있는 경우
- 태그명: a.superSavingProduct_link__nlArK


- 3번 경우 - 기본 상품명만 있는 경우
- 태그명: a.product_link__TrAac


4-2-2. 크롤링으로 가져온 정보 추출 - 2 상품 가격
/**
* 상품 가격 추출
*/
private String extractPrice(Document doc) {
Elements priceElements = doc.select(
"span.price_num__S2p_v em");
return !priceElements.isEmpty() ? priceElements.text() : null;
}상품 가격은 친절하게도 단일태그로 되어있습니다.
태그명: price_num__S2p_v

4-2-2. 크롤링으로 가져온 정보 추출 - 3 쇼핑몰
/**
* 쇼핑몰 정보 추출
*/
private String extractMall(Document doc) {
// Case 1: 텍스트 기반 쇼핑몰 정보 추출
Elements mallElements = doc.select(
"a.product_mall__hPiEH, a.superSavingProduct_mall__dEYF7, a.adProduct_mall__zeLIC");
if (!mallElements.isEmpty()) {
// title이 비어있으면 text를 사용
String mall = mallElements.attr("title").isEmpty() ? mallElements.text() : mallElements.attr("title");
if (mall != null && !mall.isEmpty()) {
return mall;
}
}
// Case 2: 이미지 태그의 alt 속성 추출
Elements mallImgElements = doc.select(
"a.product_mall__hPiEH img, a.superSavingProduct_mall__dEYF7 img, a.adProduct_mall__zeLIC img");
if (!mallImgElements.isEmpty()) {
return mallImgElements.attr("alt");
}
// Case 3: Subcase 처리 (리스트 형태 쇼핑몰 정보)
Elements mallListElements = doc.select("span.product_mall_name__MbUf3");
if (!mallListElements.isEmpty()) {
List<String> mallList = new ArrayList<>();
mallListElements.forEach(mall -> mallList.add(mall.text()));
return String.join(", ", mallList);
}
// 정보가 없는 경우 null 반환
return null;
}마지막으로 쇼핑몰 같은 경우에도 총 3가지 경우가 있었습니다. 다만 보여지는 구성이 3가지이기 때문에 case별로 나눠서 코드를 넣어줘야 합니다. 이번에도 태그를 확인하고, 각 태그별로 doc.select를 이용해 값을 추출합니다.
- 1번 경우 - 기본


- 2번 경우 - 이미지로 되어 있는 경우


- 3번 경우 - 리스트 형태 쇼핑몰 정보

- 크롤러 전체 코드 - crawler/SeleniumNaverShoppingCrawler
패키지명을 crawler로 적었지만 @Service코드라 생각하시면 됩니다!! 실제로도 Service 어노테이션이 붙어있어요.
package com.example.demo.crawler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.springframework.stereotype.Service;
import com.example.demo.dto.Product;
import java.util.ArrayList;
import java.util.List;
@Service
public class SeleniumNaverShoppingCrawler {
/**
* 네이버 쇼핑 데이터를 크롤링하여 반환
*
* @param keyword 검색 키워드
* @param page 페이지 번호
* @return List<Product> 크롤링된 상품 목록
* @throws InterruptedException 스레드 대기 시 발생할 수 있는 예외
*/
public List<Product> getShoppingData(String keyword, int page) throws InterruptedException {
// 크롤링 결과를 담을 리스트 초기화
List<Product> result = new ArrayList<>();
int num = 1; // 상품 번호 초기화
// Selenium WebDriver 설정
ChromeOptions options = new ChromeOptions(); // 크롬 옵션 객체 생성
WebDriver driver = new ChromeDriver(options); // WebDriver 객체 생성
try {
// 네이버 쇼핑 검색 URL 생성
String url = String.format(
"https://search.shopping.naver.com/search/all?pagingIndex=%d&query=%s", page, keyword);
driver.get(url); // URL로 이동
// 페이지 끝까지 스크롤
((JavascriptExecutor) driver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
Thread.sleep((int) ((Math.random() + 0.1) * 300)); // 랜덤 대기 시간 추가 (부하 방지)
// 상품 리스트 크롤링
List<WebElement> productElements = driver.findElements(By.cssSelector(".basicList_list_basis__uNBZx > div > div"));
for (WebElement element : productElements) {
// 상품 HTML 파싱 및 Product 객체 생성
Product product = parseProduct(num, element.getAttribute("innerHTML"));
if (product != null) {
result.add(product); // 결과 리스트에 추가
num++; // 상품 번호 증가
}
}
} finally {
driver.quit(); // 브라우저 종료
}
return result; // 크롤링 결과 반환
}
/**
* HTML을 파싱하여 Product 객체 생성
*
* @param num 상품 번호
* @param html 상품 정보를 담고 있는 HTML
* @return Product 객체
*/
private Product parseProduct(int num, String html) {
// Jsoup을 사용해 HTML 파싱
Document doc = Jsoup.parse(html);
// 상품 제목, 가격, 쇼핑몰 정보 추출
String title = extractTitle(doc); // 상품 제목 추출
String price = extractPrice(doc); // 상품 가격 추출
String mall = extractMall(doc); // 쇼핑몰 정보 추출
// 모든 정보가 유효한 경우에만 Product 객체 생성
if (title == null || price == null || mall == null) return null;
System.out.println("num= " + num + " ,title= " + title + " ,mall= " + mall + " ,price= " + price);
return new Product(num, title, mall, price);
}
/**
* 상품 제목 추출
*
* @param doc Jsoup으로 파싱된 HTML 문서
* @return 상품 제목 또는 null
*/
private String extractTitle(Document doc) {
// 상품 제목에 해당하는 HTML 요소 선택
Elements titleElements = doc.select(
"a.product_link__TrAac, a.superSavingProduct_link__nlArK, a.adProduct_link__NYTV9");
// title 속성이 비어 있으면 텍스트를 반환
return !titleElements.isEmpty() ? titleElements.attr("title").isEmpty()
? titleElements.text()
: titleElements.attr("title") : null;
}
/**
* 상품 가격 추출
*
* @param doc Jsoup으로 파싱된 HTML 문서
* @return 상품 가격 또는 null
*/
private String extractPrice(Document doc) {
// 상품 가격에 해당하는 HTML 요소 선택
Elements priceElements = doc.select(
"span.price_num__S2p_v em");
// 가격 텍스트 반환
return !priceElements.isEmpty() ? priceElements.text() : null;
}
/**
* 쇼핑몰 정보 추출
*
* @param doc Jsoup으로 파싱된 HTML 문서
* @return 쇼핑몰 정보 또는 null
*/
private String extractMall(Document doc) {
// Case 1: 텍스트 기반 쇼핑몰 정보 추출
Elements mallElements = doc.select(
"a.product_mall__hPiEH, a.superSavingProduct_mall__dEYF7, a.adProduct_mall__zeLIC");
if (!mallElements.isEmpty()) {
// title 속성이 비어 있으면 텍스트 반환
String mall = mallElements.attr("title").isEmpty() ? mallElements.text() : mallElements.attr("title");
if (mall != null && !mall.isEmpty()) {
return mall;
}
}
// Case 2: 이미지 태그의 alt 속성 추출
Elements mallImgElements = doc.select(
"a.product_mall__hPiEH img, a.superSavingProduct_mall__dEYF7 img, a.adProduct_mall__zeLIC img");
if (!mallImgElements.isEmpty()) {
// 이미지 태그의 alt 속성 반환
return mallImgElements.attr("alt");
}
// Case 3: Subcase 처리 (리스트 형태 쇼핑몰 정보)
Elements mallListElements = doc.select("span.product_mall_name__MbUf3");
if (!mallListElements.isEmpty()) {
// 여러 쇼핑몰 이름을 쉼표로 연결
List<String> mallList = new ArrayList<>();
mallListElements.forEach(mall -> mallList.add(mall.text()));
return String.join(", ", mallList);
}
// 정보가 없는 경우 null 반환
return null;
}
}
5. 최종 결과
http://localhost:8081/crawl2?keyword=쌀&page=1



6. 개선하면 좋은 점
1. keyword를 DB에서 받아와서 호출하기 -> crontab을 이용해 자동 호출로도 이어질 수 있겠다.
2. 결과 Product를 DB에 저장하기
3. 다른 정보들도 크롤링해서 같이 가져오기
읽어주셔서 감사합니다. 언제나 질문&피드백은 환영합니다!